

There’s this thing in digital audio called Dither. It’s the first step of lossy-ness. But it’s never talked about outside of mastering engineer shop talk. I think it’s ignored because it’s misunderstood, and frankly, would hurt sales if explained.

Dither, using the most simple explanation, is static.
Fuzz.
White noise.
It is added to digital audio files in the studio on purpose.
On purpose !?!
It is needed to cover up the nasty residue from downsampling.
Downsampling is when a digital audio file has it’s resolution reduced.
This reduction is done before getting to you, the consumer, for reasons that aren’t totally needed anymore.

Key point — this is the basis of so-called hi-res music. If your copy is the same resolution as the files were in the music studio while being created, you have a hi-res copy.
If your resolution is lower than the original, it’s probably been dithered, and compressed using a lossy codec.
Is 16/44 lossless (CD quality) hi-res?
Depends on how it was recorded.
If, in the studio, that artist, producer, mixing engineer and mastering engineer all worked with 16/44 tracks, then 16/44 is indeed hi-res. It’s the highest native res they have.
“Hi-res” actually means highest native resolution.
Chances are the studio production was done at higher than 16/44 resolution. After all, 24/48 and 24/88 resolutions have been standard since the 1990’s.
Since 2010 or so 24/96 has been common. Whatever they mixed in is the native (hi-res) version.
Upsampling doesn’t matter here.
You have the same signal after you upsample, you just have more blank space in it.
In some rare cases (like restoration of bad audio) mastering engineers will upsample to work on a project then downsample before distribution. This rare instance doesn’t affect this debate because they usually downsample without dither in those cases.
So why Dither, again?
Downsampling a complex audio signal means you have to fit that waveform into fewer datapoints. Less pixels, so to speak. Look at your computer monitor. It might display around 1280 x 720 pixels, a total of 921,600 pixels.
If that screen could only display a resolution of 800 x 600 for a total of 480,000 pixels, that’s a whopping 48% reduction in pixels!
Could you see the same detail at 800 x 600 as you could at 1280 x 720?
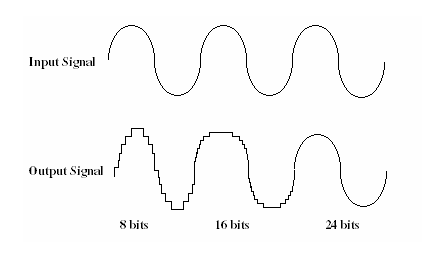
Guess what – your ears are far more accurate and attentive to loss and damage than even your eyes.
Taking an audio file from say 24/88 to 16/44 by downsampling reduces it greatly. The resulting ‘jaggies’ in the audio signal – due to the bigger ‘pixels’ – sound horrible. They can leave glitches and digital damage sounds in the file. They are in no way musical or easy to avoid.
From Wikipedia: The process of reducing bit-resolution causes quantization errors, also known as truncation distortion, which if not prevented, can sound very unpleasant
That’s why Dither was developed.
Engineers found that by applying a small amount of static or fuzz or white noise randomization to the downsampled signal, the nasty glitches went away, or were otherwise covered up.
Masking always has side effects. So they reduced the file size and covered up some of the damage with inaudible fuzz. Why is it bad? It’s not really bad.
It just is the first step of degradation from the original, and is not really needed anymore. Not in 2018 or future years.
This is all based on bandwidth restrictions. File size. That’s the only reason to downsample in the first place.

In 1978 they developed the standard of 16/44, determined to be good enough for consumer music. It had the right mix of quality sound and file size.
By their standards, the files were huge. CD’s were invented to hold all that data! A song might be 50mb. A whole album could be 500mb. That was a lot of data back then.
It would literally cost 10’s of thousands of dollars to get a hard drive big enough to hold 1 album!
We simply couldn’t afford to store, transfer, or convert high-res 24bit audio files back then.
In fact it took until the mid 90’s for professional studio to be able to afford hi-res. It took until 2010 or so for an average consumer to afford using hi-res music.
In the late-90’s, some music labels with huge archive libraries began re-converting analog masters to digital at 24bit. The amazing thing was we learned that in some cases, their original 16bit digitization efforts weren’t even complete!
It’s not just production.
Consumer music is about the playback device. Playback devices need to be affordable or no one will buy them.
The price of a DAC in the 1980’s that could convert 24bit files cost 5x as much as a DAC that could convert 16bit files.
It just wasn’t practical to use 24bit as a consumer format in the 80’s. Even if you lived with bigger files you’d need hundreds of dollars of storage space and much more expensive DAC’s.
The sad thing is that sometime in the early 21st century our chip prices, bandwidth, and price of storage all reached a level where we no longer need all this degradation of our art.
A full-resolution, stereo 24bit digital signal takes as much bandwidth as a Netflix HD stream. There’s millions of them going 24/7.
But people still degrade their music, 2, 3, even 4 times before it hits their ear. #Sad.
Instead of going to 11 they decided to dial it back to 5. And keep it there forever.
